昨天我們進行LangChain結合Diagram as Code RAG生成雲端架構圖的初步展示,但對於文件管理來說,要在本地端管理越來越多的文件,實在難以執行,因此我們今天會介紹可以和LangChain整合的雲端資料庫和Retrievers
我們可以先看LangChain支援的Retrievers有哪些
https://python.langchain.com/v0.2/docs/integrations/retrievers/
https://aws.amazon.com/bedrock/knowledge-bases/
AWS Bedrock最大的優勢在於整合多個模型提供商的模型可以進行使用
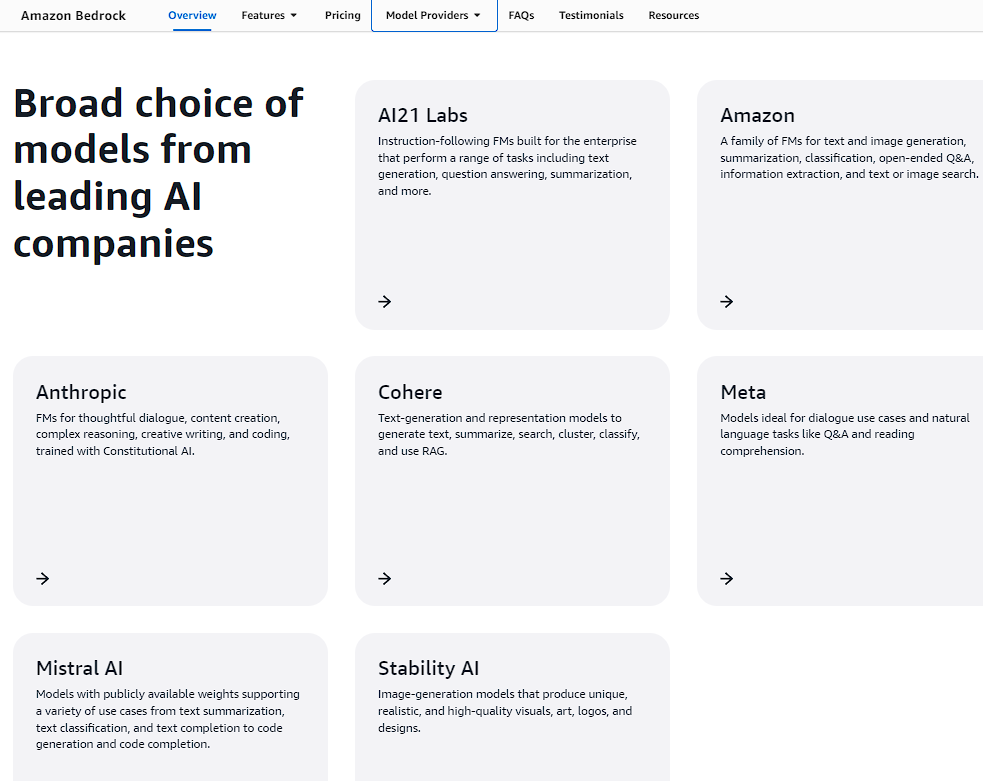
當然不是每個模型提供商都有embedding model,這裡展示幾個我發現有embedding model的模型


串接上,只要選擇好資料來源和embedding model成功建立knowledge_base,使用id就能串接
from langchain_aws.retrievers import AmazonKnowledgeBasesRetriever
retriever = AmazonKnowledgeBasesRetriever(
knowledge_base_id="",
retrieval_config={"vectorSearchConfiguration": {"numberOfResults": 4}},
)
https://azure.microsoft.com/en-us/products/ai-services/ai-search/
Azure的AI Search也有將文件匯入並且向量化的功能,並提供搜尋,只不過embedding model的選擇就沒那麼多
有興趣可以參考這兩篇文章
https://learn.microsoft.com/zh-tw/azure/search/vector-search-overview
https://learn.microsoft.com/zh-tw/azure/search/search-get-started-portal-import-vectors?tabs=sample-data-storage%2Cmodel-aoai%2Cconnect-data-storage
串接上也稍微複雜,主要和AI_SEARCH_SERVICE_NAME以及AI_SEARCH_INDEX_NAME有關係
import os
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain_community.retrievers import AzureAISearchRetriever
from langchain_community.vectorstores import AzureSearch
from langchain_openai import AzureOpenAIEmbeddings, OpenAIEmbeddings
from langchain_text_splitters import TokenTextSplitter
os.environ["AZURE_AI_SEARCH_SERVICE_NAME"] = "<YOUR_SEARCH_SERVICE_NAME>"
os.environ["AZURE_AI_SEARCH_INDEX_NAME"] = "langchain-vector-demo"
os.environ["AZURE_AI_SEARCH_API_KEY"] = "<YOUR_SEARCH_SERVICE_ADMIN_API_KEY>"
azure_endpoint: str = "<YOUR_AZURE_OPENAI_ENDPOINT>"
azure_openai_api_key: str = "<YOUR_AZURE_OPENAI_API_KEY>"
azure_openai_api_version: str = "2023-05-15"
azure_deployment: str = "text-embedding-ada-002"
embeddings = AzureOpenAIEmbeddings(
model=azure_deployment,
azure_endpoint=azure_endpoint,
openai_api_key=azure_openai_api_key,
)
vector_store: AzureSearch = AzureSearch(
embedding_function=embeddings.embed_query,
azure_search_endpoint=os.getenv("AZURE_AI_SEARCH_SERVICE_NAME"),
azure_search_key=os.getenv("AZURE_AI_SEARCH_API_KEY"),
index_name="langchain-vector-demo",
)
明天我們將會介紹AWS Kendra 、 GCP AgentBuilder 等 非向量搜尋的Retrievers,接著我們會實際操作AgentBuilder串接作為示範

